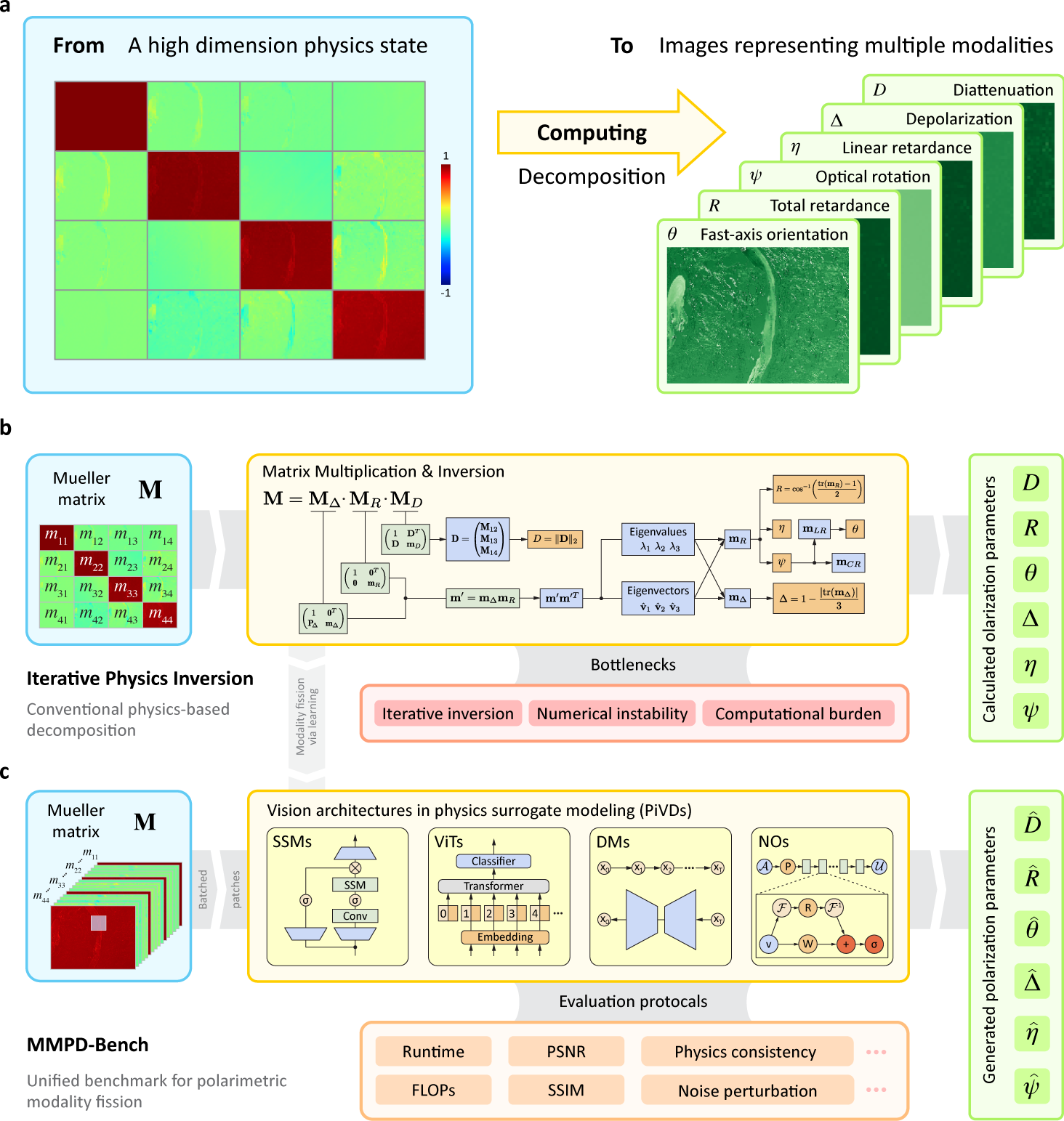
Method
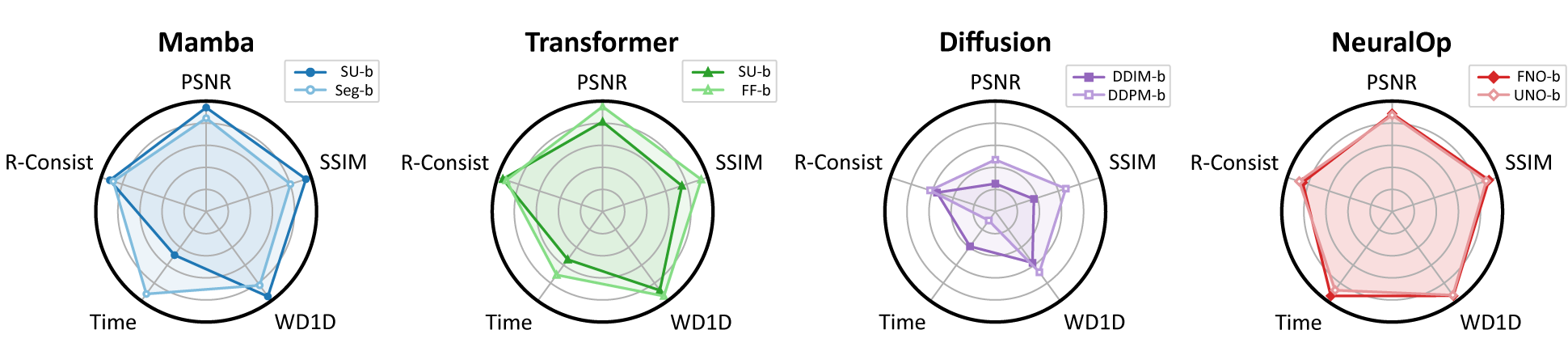
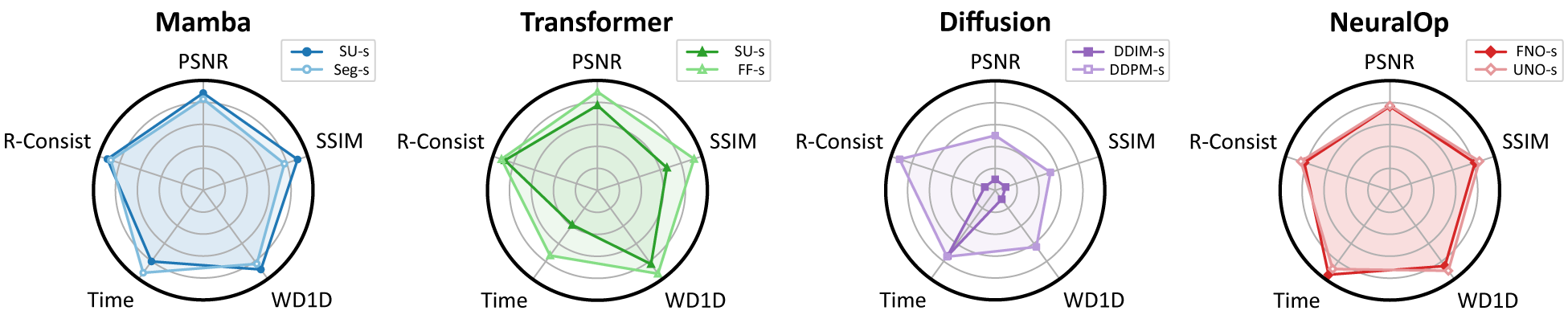
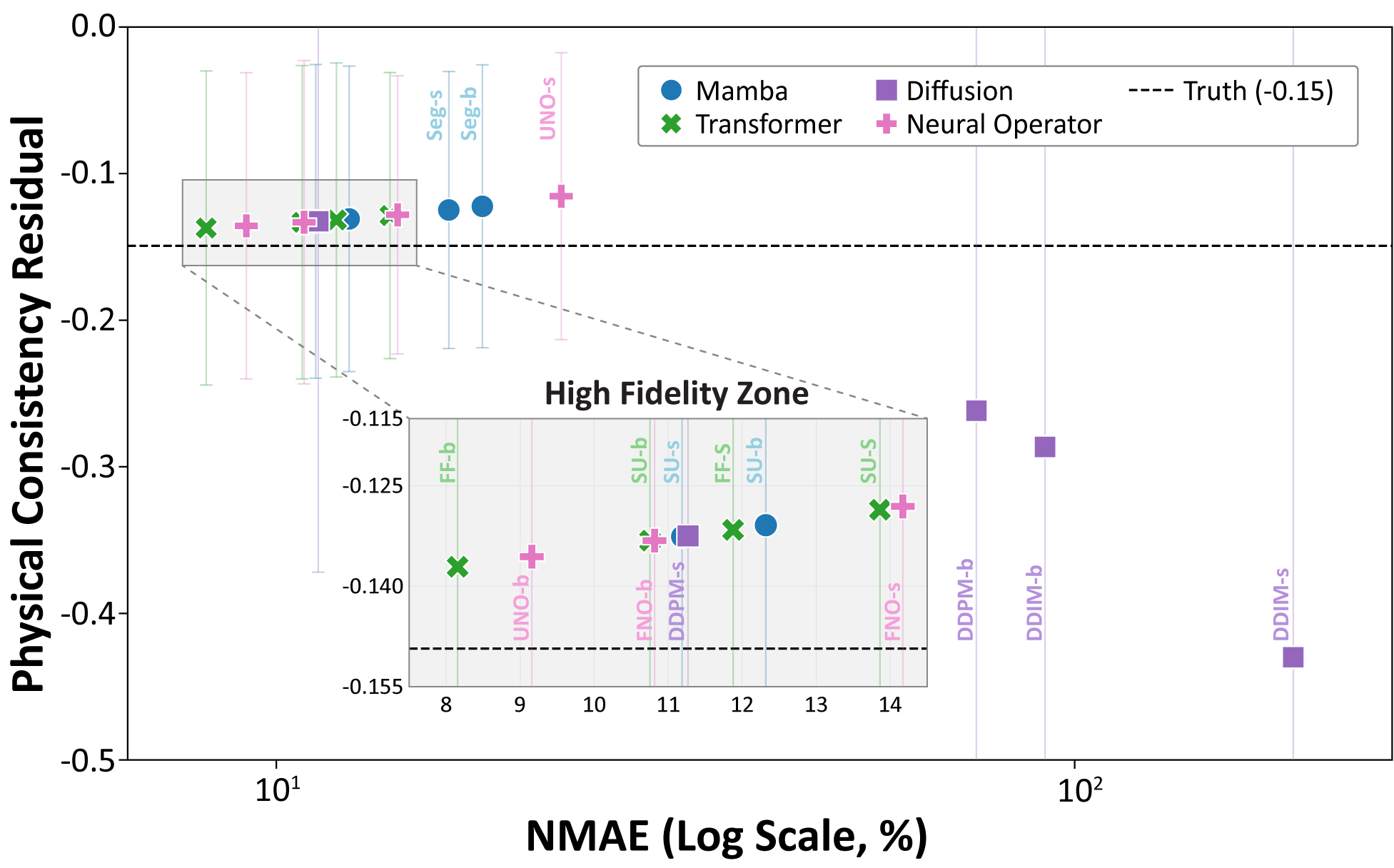
How MMPD-Bench Works
A spatially resolved 4×4 Mueller matrix observation describes the transformation of the polarisation state under the Stokes–Mueller formalism, and is decomposed into six physically interpretable parameters — diattenuation (D), depolarisation (Δ), linear retardance (η), total retardance (R), fast-axis orientation (θ), and optical rotation (ψ). Conventional MMPD relies on physics-based numerical inversion (Lu–Chipman), which can introduce numerical instability and computational burden at large scale. MMPD-Bench reframes this process as a modality-fission problem and benchmarks deep surrogate models — state space models, vision transformers, diffusion models, and neural operators — under unified evaluations of fidelity, statistical alignment, physical consistency, robustness, and efficiency.